
Table of Contents
소프트웨어 시스템이란 정책을 기술한 것이다. 실제로 컴퓨터 프로그램의 핵심부는 이게 전부다.
대다수의 주요 시스템에서 하나의 정책은 이 정책을 서술하는 여러 개의 조그만 정책들로 쪼갤 수 있다.
소프트웨어 아키텍처를 개발하는 기술에는 이러한 정책을 신중하게 분리하고, 정책이 변경되는 양상에 따라 정책을 재편성하는 일도 포함된다. 동일한 이유로 동일한 시점에 변경되는 정책은 동일한 수준에 위치하며, 동일한 컴포넌트에 속해야 한다. 서로 다른 이유로, 혹은 다른 시점에 변경되는 정책은 다른 수준에 위치하며, 반드시 다른 컴포넌트로 분리해야 한다.
흔히 아키텍처 개발은 재편성된 컴포넌트들을 비순환 방향 그래프로 구성하는 기술을 포함한다. 그래프에서 정점은 동일한 수준의 정책을 포함하는 컴포넌트에 해당한다. 방향이 있는 간선은 컴포넌트 사이의 의존성을 나타낸다. 간선은 다른 수준에 위치한 컴포넌트를 서로 연결한다.
이러한 의존성은 소스코드, 컴파일타임의 의존성이다.
좋은 아키텍처라면 각 컴포넌트를 연결할 때 의존성의 방향이 컴포넌트의 수준을 기반으로 연결되도록 만들어야 한다. 즉, 저수준 컴포넌트가 고수준 컴포넌트에 의존하도록 설계되어야 한다.
수준
‘수준(level)’을 엄밀하게 정의하자면 ‘입력과 출력까지의 거리’다. 시스템의 입력과 출력 모두로부터 멀리 위치할수록 정책의 수준은 높아진다. 입력과 출력을 다루는 정책이라면 시스템에서 최하위 수준에 위치한다.
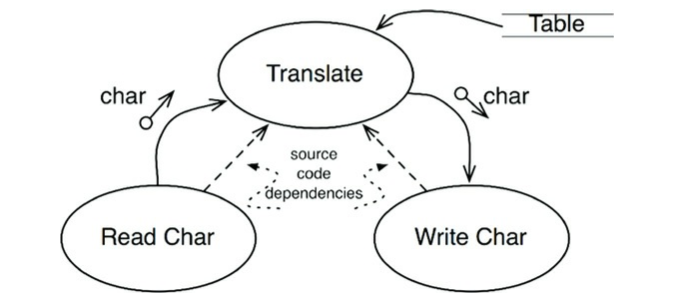 번역 컴포넌트는 이 시스템에서 최고 수준의 컴포넌트이다. 입력과 출력에서 가장 멀리 떨어져 있기 때문이다.
번역 컴포넌트는 이 시스템에서 최고 수준의 컴포넌트이다. 입력과 출력에서 가장 멀리 떨어져 있기 때문이다.
주목할 점은 데이터 흐름과 소스코드 의존성이 항상 같은 방향을 가리키지 않는다는 사실이다.
아래와 같이 암호화 프로그램을 작성하면 잘못된 아키텍처이다.
1
2
3
4
function encrypt() {
while(true)
writeChar(translate(readChar()));
}
고수준인 encrypt 함수가 저수준인 readChar와 writeChar 함수에 의존하기 때문이다.
아래의 클래스 다이어그램은 이 시스템의 아키텍처를 개선해본 모습이다. 주목할 점은 Encrypt 클래스, CharWriter와 CharReader 인터페이스를 둘러 싸고 있는 점선으로 된 경계다. 이 경계를 횡단하는 의존성은 모두 경계 안쪽으로 향한다. 이 경계로 묶인 영역이 이 시스템에서 최고 수준의 구성요소다.
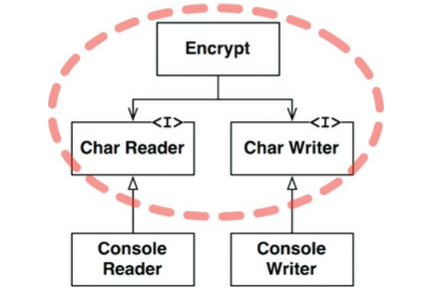
이 구조에서 고수준의 암호화 정책을 저수준의 입력/출력 정책으로부터 분리시킨 방식에 주목하자. 입력과 출력에 변화가 생기더라도 암호화 정책은 거의 영향을 받지 않기 때문이다.
정책을 컴포넌트로 묶는 기준은 정책이 변경되는 방식에 달려있다는 사실을 상기하자. 단일 책임 원칙과 공통 폐쇄 원칙에 따르면 동일한 이유로 동일한 시점에 변경되는 정책은 함께 묶인다.
이처럼 모든 소스코드 의존성의 방향이 고수준 정책을 향할 수 있도록 정책을 분리했다면 변경의 영향도를 줄일 수 있다.
이 논의는 저수준 컴포넌트가 고수준 컴포넌트에 플러그인되어야 한다는 관점으로 바라볼 수도 있다.

결론
여기에서 설명한 정책에 대한 논의는 단일 책임 원칙, 개방 폐쇄 원칙, 공통 폐쇄 원칙, 의존성 역전 원칙, 안정된 의존성 원칙, 안정된 추상화 원칙을 모두 포함한다.