
여기서 이야기하고자 하는 인덱스란, 카프카의 OffsetIndex, TimeIndex이다.
해당 인덱스들은 모두 파일로 관리되는데, 카프카의 로그 파일(baseoffset.log) 마다 한 벌씩 생성된다.
각각의 파일은 baseoffset.index, baseoffset.timeindex이다.
위의 baseoffset은 10자리의 숫자로 구성되며, 각 로그 파일의 시작 레코드 offset이다.
카프카의 로그 파일이 커지면 특정 레코드를 찾기 위해 로그 파일 전체를 뒤져야 하는데, 이는 효율이 떨어진다.
한 로그 파일 안에서 특정 레코드를 효율적으로 찾기 위해서 사용하는 방법이 인덱스다.
각 인덱스의 용도는 다음과 같다.
- OffsetIndex는 레코드의 Offset으로 로그 파일의 Position 찾기
- TimeIndex는 레코드의 Timestamp로 레코드의 Offset 찾기
다음 그림을 보면 각 인덱스와 로그 파일의 대략적인 관계를 알수 있다.
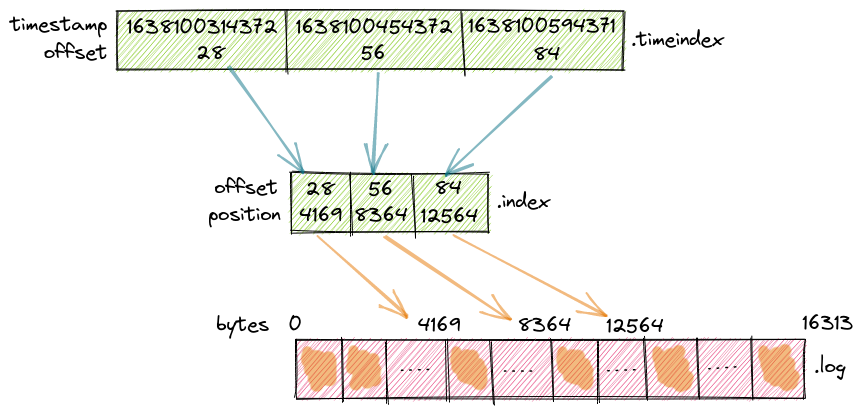
(출처: https://strimzi.io/blog/2021/12/17/kafka-segment-retention)
그림과 같이 인덱스를 통해서 timestamp나 레코드 offset을 기준으로 로그 파일의 position을 찾을 수 있다.
단, 인덱스 파일은 모든 레코드의 인덱스를 포함하진 않고 카프카 설정값(index.interval.bytes)을 기준으로 최소 간격을 유지하며 인덱스를 생성한다.
그래서 인덱스를 통해 찾은 position 위치 부터 로그 파일에서 찾고자 하는 Offset의 레코드를 찾는다.
인덱스와 캐시
카프카 인덱스는 기본적으로 이진탐색 알고리즘을 사용한다.
하지만 일반적인 이진탐색 알고리즘은 캐시에 적합하지 않다.
여기서 캐시는 OS의 페이지 캐시이다.
페이지 캐시와 카프카 인덱스의 특징 몇 가지만 간단히 보자.
- 카프카 인덱스 접근 패턴
- 대부분 인덱스의 마지막에서 발생
- 추가는 카프카는 인덱스의 끝에서 발생
- 검색은 대부분 카프카의 인덱스 끝 부분에서 발생
- 오래된 로그를 소비할 수 있지만, 시간이 지나면 최신 로그를 소비하게 됨
- 카프카 인덱스는 파일
- Memory Mapped Files로 메모리에 사상
- OS 페이지 캐시 대상
- OS의 페이지 캐시
- LRU 형태의 교체 알고리즘 사용
카프카 인덱스 접근 패턴은 LRU 교체 알고리즘과 잘 맞는다.
하지만 이진탐색 알고리즘은 오래된 인덱스도 조회하게 되어 문제가 발생한다.
하지만 카프카 인덱스는 이진탐색 알고리즘을 사용해 페이지 캐시 히트율을 높게 유지하며 검색을 지원한다.
Warm Section
캐시에 적합한 검색의 핵심은 Warm Section이다.
Warm Section은 자주 조회해서 해당 부분의 페이지가 페이지 캐시에 최대한 존재하도록 한 부분이다.
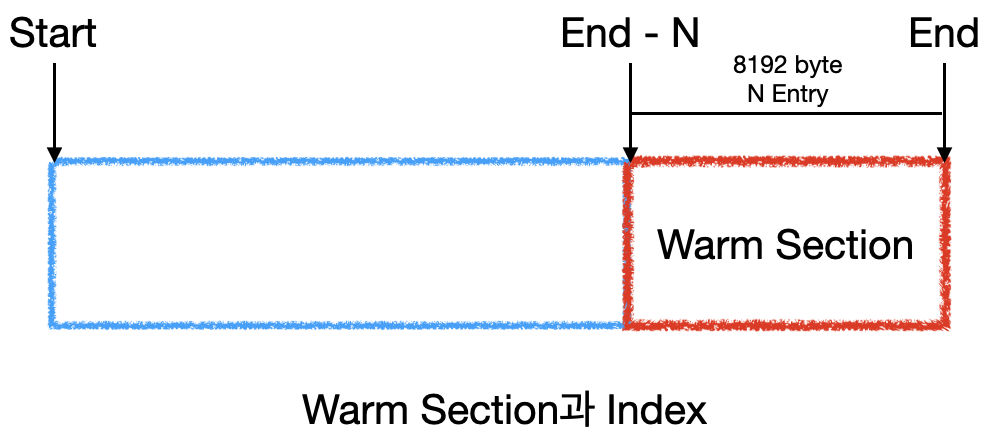
- 마지막 N개의 Index Entry를 의미
- OS 페이지 캐시에 최대한 올라가 있도록 유도된 구간
- 크기는 8192 Byte로 고정
- Index Entry 개수 : 8192 / ENTRY_SIZE
- Entry Size : 8 Byte(OffsetIndex)와 12 Byte(TimeIndex)
index.interval.bytes설정값이 커버하는 로그 범위에 영향- 최소 해당 설정값 간격으로 Index Entry 생성
- 기본값은 4096로 4 KB
- 기본값일 때, 각 인덱스의 대략적인 로그 파일 커버 범위
- OffsetIndex : 4 MB
- TimeIndex : 2.7 MB
검색
카프카는 Warm Section인 부분과 아닌 부분을 나누어 이진탐색을 수행한다.
1
2
3
4
5
6
7
8
9
10
11
int firstHotEntry = Math.max(0, entries - 1 - warmEntries());
// warm section 조회
if (compareIndexEntry(parseEntry(idx, firstHotEntry), target, searchEntity) < 0) {
return binarySearch(..., firstHotEntry, entries - 1);
}
...
// 그 외 조회
return binarySearch(..., 0, firstHotEntry);
- Warm Section 조회 시,
indexEntry(end),indexEntry(end-N),indexEntry((end*2 -N)/2)의 페이지 조회parseEntry(idx, entry)코드가 파일을 메모리로 사상한 영역을 접근하여 페이지 히트indexEntry(end-N)은 Warm Section 구분을 위해 매번 조회indexEntry((end*2 -N)/2)은 이진탐색 시작 시 매번 접근indexEntry(end)은 인덱스 추가 및 탐색 시 접근
- 대부분의 Processor의 최소 페이지 크기는 4096 byte(2018년도 기준이라 함)
- Warm Section은 고정 8192 Byte 크기
- Warm Section 범위의 Page는 3개 이하
- Warm Section 조회 시, 모든 Warm Section 구간이 페이지 케시에 올라오도록 유도됨
binarySearch는 기본적인 이진탐색 구현
결론
카프카의 인덱스 검색 연산은 Warm Section과 아닌 Section을 나누어서 이진탐색을 수행한다.
모든 삽입연산은 인덱스의 끝 부분에서 발생하고, 대부분의 검색은 Warm Section에서 발생하게 된다.
결과적으로 카프카 인덱스 파일 영역을 Memory Mapped Files를 통해서 접근하고, 8192 byte의 Warm Section으로 구분해 해당 Section이 OS 페이지 캐시를 최대한 활용하도록 설계되었다.