
Table of Contents
들어가기
계층 모델, 관계형 모델, 문서 데이터베이스, 그래프 데이터베이스
데이터 모델은 소프트웨어 개발에서 중요한 부분이다.
- 소프트웨어가 어떻게 작성될지
문제를 어떻게 생각해야 하는지에 대해 지대한 영향 - 각 계층은 명확한 데이터 모델을 제공해 하위 계층의 복잡성을 추상화
이런 추상화는 다른 그룹의 사람들이 효율적으로 함께 일할 수 있게끔 함 - 다양한 유형의 데이터 모델이 존재
각 데이터 모델은 사용 방법에 대한 가정을 나타냄 - 소프트웨어가 할 수 있는 일과 할 수 없는 일에 영향
그래서 목적에 적합한 데이터 모델을 선택하는 일은 상당히 중요하다.
이제 각 데이터 모델과 질의 언어를 살펴보고 영역별 장단점을 알아본다.
이를 통해서 우리는 적합한 데이터 모델을 선택하는 한 척도를 살펴볼 수 있다.
관계형 모델과 문서 모델
객체 관계형 불일치
- 임피던스 불일치
데이터를 관계형 테이블에 저장하려면 애플리케이션 코드와 데이터베이스 모델 객체 사이에 거추장스러운 전환 계층이 필요하다.
이렇듯 데이터베이스 모델과 프로그래밍 언어 모델과의 차이로 인해서 발생하는 문제들을 말하는 단어이다.
예제로 나온 이력서를 표현하는 경우
사람별로 경력에 넣을 직업이 여러개이며 학력 기간과 연락처 정보도 다양하다.
이런 항목들은 일대다 관계이다.
관계형 데이터베이스 는 이 관계를 다양한 방법으로 나타낼 수 있다.
- 관계형 데이터베이스의 일반적인 방법으로 정규화 표현
- 구조화된 데이터타입과 XML 데이터 사용(SQL 최신 버전)
- JSON, XML문서로 부호화해 텍스트 컬럼에 저장 -> 애플리케이션에서 처리
이력서 같은 데이터 구조는 모든 내용을 갖추고 있는 문서라서 JSON 표현에 매우 적합하다.
문서 지향 데이터베이스 는 JSON 데이터 모델을 지원한다.
JSON 모델이 임피던스 불일치를 줄인다고 생각하지만, 데이터 부호화 형색으로서 JSON이 가진 문제도 있다.
JSON 표현은 관계형 데이터베이스의 다중 테이블 스키마보다 더 나은 지역성을 갖는다.
다대일과 다대다 관계
데이터베이스 모델에 실제 문자열이 아닌 ID로 주어지는 경우가 있다.
ID로 주어진 경우 연관된 테이블에서 조인을 통해서 실제 데이터를 해결한다.
ID나 텍스트 문자열의 저장 여부는 중복의 문제다.
쓰기 오버헤드와 불일치
ID를 사용하는 장점 은 ID 자체는 아무런 의미가 없기 때문에 변경할 필요가 없다.
의미를 가지는 경우라면 미래에 언젠가는 변경해야 할 수도 있다.
이런 중복을 제거하는 일이 데이터베이스의 정규화 이면에 놓인 핵심 개념이다.
중복된 데이터를 정규화하려면 다대일 관계가 필요
하지만 문서 모델 에서 다대일 관계는 적합하지 않다.
- 관계형 데이터베이스
조인이 쉽기 때문에 ID로 다른 테이블의 로우를 참조하는 방식은 일반적 - 문서 데이터베이스
일대다 트리 구조를 위해 조인이 필요하지 않지만 조인에 대한 지원이 보통 약하다.
데이터베이스 자체에서 조인을 지원하지 않으면 데이터베이스에 대한 다중 질의를 만들어서 애플리케이션 코드에서 조인을 흉내내야 한다.
또한 애플리케이션 초기 버전이 조인 없는 문서 모델에 적합하더라도 애플리케이션에 기능을 추가하면서 데이터는 점차 상호 연결되는 경향이 있다.
문서 데이터베이스는 역사를 반복하고 있나?
1970년대 IBM의 정보 관리 시스템(IMS)는 계층 모델 이라 부르는 상당히 간단한 데이터 모델을 사용했다.
계층 모델은 문서 데이터베이스에서 사용하는 JSON 모델과 놀랍게도 비슷하다.
문서 데이터베이스처럼 IMS도 일대다 관계에서 잘 동작하며, 다대다 관계 표현은 어려웠고 조인은 지원하지 않았다.
계층 모델의 한계를 해결하기 위해 다양한 해결책이 제안됐다.
- 관계형 모델
- 네트워크 모델
네트워크 모델
코다실이라 불리는 위원회에서 표준화했다.
레코드 간 연결은 외래 키보다는 프로그래밍 언어의 포인터와 더 비슷하다.
레코드에 접근하는 유일한 방법은 접근 경로 로 불리며
최상위 레코드에서부터 연속된 연결 경로를 따르는 방법이다.
수동 접근 경로 선택은 1970년대에는 매우 제한된 하드웨어 성능을 가장 효율적으로 사용할 수 있었지만
데이터베이스 질의와 갱신을 위한 코드가 복잡하고 유연하지 못한 문제가 있었다.
관계형 모델
단순히 튜플(로우)의 컬렉션이 전부다.
얽히고설킨 중첩 구조와 데이터를 찾을 때 따라가야 할 복잡한 접근 경로가 없다.
질의 최적화기(Query Optimizer)는 질의의 어느 부분을 어떤 순서로 실행할지를 결정하고 사용할 색인을 자동으로 결정한다.
이 선택이 실제로 접근 경로 다.
하지만 큰 차이점은 접근 경로를 애플리케이션 개발자가 아니라 질의 최적화기가 자동으로 만든다는 점 이다.
새로운 방식으로 데이터를 질의하고 싶은 경우, 새로운 색인을 선언하기만 하면된다.
관계형 모델은 애플리케이션에 새로운 기능을 추가하는 작업이 훨씬 쉽다.
문서 데이터베이스와의 비교
계층 모델과 유사한 점
- 문서 데이터베이스는 별도의 테이블이 아닌 상위 레코드 내에 중첩된 레코드를 저장
계층 모델과 다른 점
- 다대일과 다대다 관계를 표현할 때 관계형 데이터베이스와 문서형 데이터베이스는 근본적으로 다르지 않다.
둘 다 관련 항목은 고유한 식별자로 참조(관계형 모델 = 외래키, 문서 모델 = 문서 참조)
관계형 데이터베이스와 오늘날의 문서 데이터베이스
데이터 모델의 차이점에만 집중해서 보자.
- 문서 데이터 모델을 선호하는 이유
- 스키마 유연성
- 지역성에 기인한 더 나은 성능
- 일부 애플리케이션의 경우 애플리케이션에서 사용하는 데이터 구조와 더 가깝기 때문
- 관계형 모델을 선호하는 이유
- 조인, 다대일, 다대다 관계를 더 잘 지원함
어떤 데이터 모델이 애플리케이션 코드를 더 간단하게 할까?
문서 모델이 더 간단한 경우
- 애플리케이션의 데이터가 문서와 비슷한 구조일 경우
- 문서가 너무 깊게 중첩되지 않는 경우(일반적으로)
문서 모델은 문서 내 중첩 항목을 바로 참조할 수 없는 제한이 있다. - 다대다 관계가 필요 없는 경우
미흡한 조인 지원은 애플리케이션에 따라 문제가 아닐 수도 있다.
애플리케이션에서 다대다 관계를 사용한다면 문서모델은 매력이 떨어진다.
비정규화로 조인의 필요성 줄이기가 가능하지만 애플리케이션 코드에서 추가적인 작업이 필요해진다.
이런 경우 문서 모델을 사용해서 더 복잡한 애플리케이션 코드와 나쁜 성능으로 이어질 수 있다.
일반적으로 어떤 데이터 모델이 애플리케이션 코드를 더 간단하게 만드는지 말할 수 없다.
데이터 항목 간에 존재하는 관계 유형에 따라 다르다.
상호 연결이 많은 데이터의 경우 관계형 모델은 무난하며 그래프 모델은 매우 자연스럽다.
문서 모델에서의 스키마 유연성
보통 문서 데이터베이스와 관계형 데이터베이스에서 지원하는 JSON은 문서의 데이터에 어떤 스키마를 강요하지 않는다.
보통 관게형 데이터베이스에서 제공하는 XML은 선택적으로 스키마 유효성 검사를 포함할 수 있다.
문서 데이터베이스는 종종 스키마리스(schemaless)로 불리지만 이는 오해의 소지가 있다.
데이터를 읽는 코드는 보통 구조의 유형을 어느 정도 가정한다.
즉, 암묵적인 스키마가 있지만 데이터베이스는 이를 강요하지 않는다.
- 쓰기 스키마(schema-on-write)
스키마는 명시적이고 데이터베이스는 쓰여진 모든 데이터가 스키마를 따르고 있음을 보장 - 읽기 스키마(schema-on-read)
암묵적이고 데이터를 읽을 때만 해석된다.
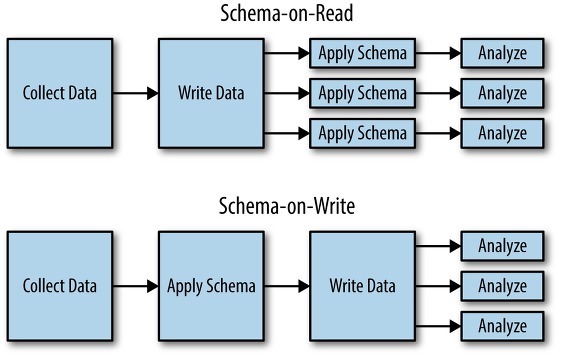
출처 : https://www.oreilly.com/content/hadoop-what-you-need-to-know
이런 접근 방식 차이는 애플리케이션이 데이터 타입을 변경하고자 할 때 특히 뚜렷이 나타난다.
- 문서 데이터베이스
애플리케이션에서 예전 문서를 읽은 경우 처리하는 코드만 있으면 된다. - “정적 타입”의 데이터베이스(RDB 등)
마이그레이션 작업 필요
읽기 스키마 접근 방식은 컬렉션 안의 항목이 어떤 이유로 모두 동일한 구조가 아닐 때 유리하다.
질의를 위한 데이터 지역성
자주 전체 문서에 접근해야 할 때 저장소 지역성(storage locality) 을 활용하면 성능 이점이 있다.
- 디스크 탐색이 적게 필요함
지역성의 이점은 한 번에 해당 문서의 많은 부분을 필요로 하는 경우에만 적용된다.
- 적은 부분만 접근해도 전체 문서를 적재해야 함.
- 문서를 갱신할 때도 보통 전체 문서를 재작성해야 함. (부호화된 문서의 크기를 바꾸지 않는 수정은 쉽게 수행)
이런 이유로 일반적으로 문서를 아주 작게 유지하면서 문서의 크기가 증가하는 쓰기를 피하라고 권장한다.
지역성을 위해 관련 데이터를 함께 그룹화하는 개념이 문서 모델에만 국한되지 않는다.
- 구글의 스패너 데이터베이스
- 오라클의 다중 테이블 색인 클러스터 테이블(multi-table index cluster table)
- 빅테이블 데이터모델의 컬럼 패밀리(column-family) 개념
문서 데이터베이스와 관계형 데이터베이스의 통합
두 데이터베이스는 시간이 지남에 따라 점점 더 비슷해지고 있다.
데이터를 위한 질의 언어
SQL은 선언형 질의언어, IMS와 코다실은 명령형 코드로 질의 한다.
일반적으로 많이 사용하는 프로그래밍 언어가 명령형 언어다.
1
2
3
4
5
6
7
8
9
function getSharks() {
var sharks = [];
for (var i = 0; i < animals.length; i++) {
if (animals[i].family === "Sharks") {
sharks.push(animals[i]);
}
}
return sharks;
}
SQL은 관계 대수의 구조를 상당히 유사하게 따랐다.
1
SELECT * FROM animals WHERE family = 'Sharks';
SQL이나 관계 대수 같은 선언형 질의 언어는 목표를 달성하기 위한 방법이 아니라
알고자 하는 데이터의 패턴, 즉 결과가 충족해야 하는 조건과 데이터를 어떻게 변환할지를 지정하기만 하면 된다.
또한 질의의 다양한 부분을 질의 최적화기 가 처리한다.
선언형 언어는 간결하고 쉽게 작업할 수 있다.
중요한 점 은 데이터베이스 엔진의 상세 구현이 숨겨져 있어,
질의를 변경하지 않고도 데이터베이스 시스템의 성능을 향상시킬 수 있다는 점이다.
선언형 언어인 SQL은 기능적으로 더 제한적이다.
이러한 사실은 데이터베이스가 최적화할 수 있는 여지를 더 많이 준다 는 의미다.
선언형 언어는 종종 병렬 실행에 적합 하다.
결과를 결정하기 위한 알고리즘을 지정하는 게 아니라 결과의 패턴만 지정하기 때문에 병렬 실행으로 더 빨라질 가능성이 크다.
웹에서의 선언형 질의
선언형 질의 언어의 장점은 데이터베이스에만 국한되지 않는다.
CSS와 XSL이 문서의 스타일을 지정하기 위한 선언형 언어이다.
스타일을 적용하려는 엘리멘트의 패턴을 선언하면 된다.
명령형인 자바스크립트에서 DOM API를 사용했을 때 보다 코드량이 상당히 줄어들 뿐만 아니라 여러 가지 문제들을 해결해준다.
맵리듀스 질의
많은 컴퓨터에서 대량의 데이터를 처리하기 위한 프로그래밍 모델이다.
많은 문서를 대상으로 읽기 전용 질의를 수행할 때 사용한다.
선언형 질의 언어로 완전한 명령형 질의 API도 아닌 그 중간 정도에 있다.
질의 로직은 처리 프레임워크가 반복적으로 호출하는 조각 코드로 표현한다.
여러 프로그래밍 언어에 있는 map과 reduce 함수를 기반으로 한다.
SQL과 비교해보자면 아래와 같다.
1
2
3
4
5
SELECT date_trunc('month', observation_timestamp) AS observation_month,
sum(num_animals) AS total_animals
FROM observations
WHERE family = 'Sharks'
GROUP BY observation_month;
위의 SQL을 몽고DB의 맵리듀스 기능을 이용해 다음과 같이 표현할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
db.observations.mapReduce(
function map() {
var year = this.observationTimestamp.getFullYear();
var month = this.observationTimestamp.getMonth() + 1;
emit(year + "-" + month, this.numAnimals);
},
funcation reduce(key, values) {
return Array.sum(values);
},
{
query: { family: "Sharks" },
out: "monthlySharkReport"
}
);
몽고DB의 map과 reduce 함수는 수행할 때 약간의 제약 사항이 있다.
- 두 함수는 순수(pure) 함수
즉, 입력으로 전달된 데이터만 사용 - 추가적인 데이터베이스 질의를 수행할 수 없다.
- 부수 효과가 없어야 한다.
이런 제약 사항 때문에 데이터베이스가 임의 순서로 어디서나 이 함수를 실행할 수 있고 장애가 발생해도 함수를 재실행할 수 있다.
맵리듀스는
- 클러스터 환경에서 분산 실행을 위한 저수준 프로그래밍 모델
하지만 맵리듀스를 사용하지 않은 분산 SQL 구현도 많다.
SQL이 단일 장비에서 수행해야 하는 제한이 없으며 맵리듀스가 분산 질의 실행에 대한 독점권을 가진 것도 아니다. - 질의 중간에 자바스크립트 코드를 사용할 수 있다는 점은 고급 질의가 가능한 훌륭한 기능
하지만 일부 SQL 데이터베이스도 자바스크립트 함수로 확장될 수 있다.
몽고DB의 집계 파이프라인(aggregation pipeline) 선언형 질의 언어 지원 이유
- 맵리듀스의 사용성 문제 는 map과 reduce 함수를 신중하게 작성해야 한다
이는 종종 하나의 질의를 작성하는 것보다 어렵다. - 선언형 질의 언어는 질의 최적화기가 질의 성능을 높일 수 있는 기회를 제공
집계 파이프라인 언어
- 표현 측면에서 SQL의 부분 집합과 유사
- JSON 기반 구문을 사용(SQL의 영어 문장 스타일 구문과 달리)
그래프형 데이터 모델
다대다 관계가 매우 일반적이라면,
관계형 모델이 단순한 다대다 관계를 다룰 수 있다.
데이터 간 연결이 복잡해지면 그래프로 데이터를 모델링하는 편이 더 자연스럽다.
그래프는 두 유형의 객체로 이뤄진다.
- 정점(vertex) = 노드나 엔티티라고도 한다.
- 간선(edge) = 관계나 호(arc)라고도 한다.
일반적으로 그래프 상에서 동작하는 알고리즘은 “자동차 내비게이션 시스템”, “페이지랭크”가 있다.
그래프 모델
- 속성 그래프 모델 : Neo4j, Titan InfiniteGraph
- 트리플 저장소 모델 : Datomic, Allegrograph
그래프용 질의 언어
- 선언형 질의 언어 : Cypher, SPARQL, Datalog
- 명령형 질의 언어 : Gremlin
그래프 처리 프레임워크 Pregel가 있다.
지금부터 속성 그래프 모델, 트리플 저장소 모델, 선언형 질의 언어들에 대해서 살펴본다.
아래 그림은 설명에서 사용하는 데이터 예제
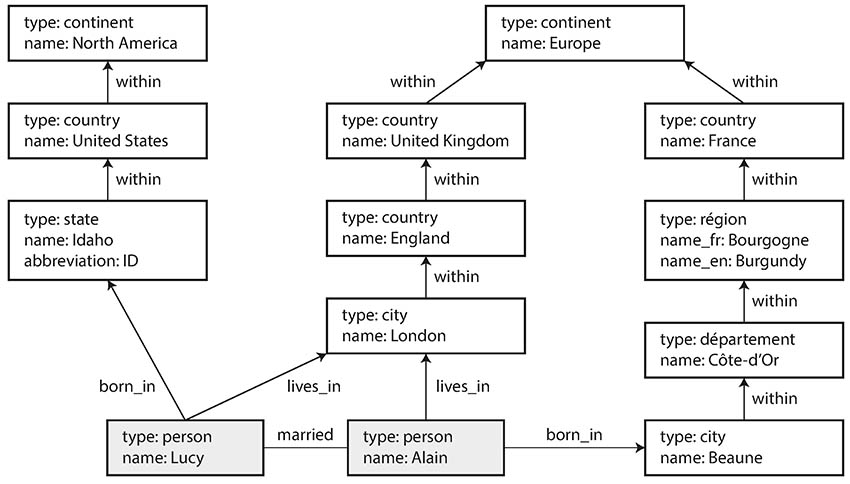
그림 1
출처 : https://oracle-patches.com/en/databases/graph-like-data-models-full-description-with-examples
속성 그래프
정점을 구성하는 요소
- 고유한 식별자
- 유출(outgoing) 간선 집합
- 유입(incoming) 간선 집합
- 속성 컬렉션(키-값 쌍)
간선을 구성하는 요소
- 고유한 식별자
- 간선이 시작하는 정점(꼬리 정점)
- 간선이 끝나는 정점(머리 정점)
- 두 정점 간 관계 유형을 설명하는 레이블
- 속성 컬렉션(키-값 쌍)
두 개의 관계형 테이블로 구성된 그래프 저장소를 생각해보면 아래와 같다.
예제 1 관계형 스키마를 사용해 속성 그래프 표현
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
CREATE TABLE vertices (
vertex_id integer PRIMARY KEY,
properties json
);
CREATE TABLE edges (
edge_id integer PRIMARY KEY,
tail_vertex integer REFERENCES vertices (vertex_id),
head_vertex integer REFERENCES vertices (vertex_id),
label text,
properties json
);
CREATE INDEX edges_tails ON edges (tail_vertex);
CREATE INDEX edges_heads ON edges (head_vertex);
이 모델의 중요한 점
- 정점은 다른 정점과 간선으로 연결
특정 유형과 관련 여부를 제한하는 스키마가 없다. - 정점이 주어지면 정점의 유입과 유출 간선을 효율적으로 찾고 그래프를 순회
- 다른 유형의 관계는 서로 다른 label을 사용
단일 그래프에 다른 유형의 정보를 저장하면서 데이터 모델을 깔끔하게 유지
그림 1과 같이 위의 기능을 통해 그래프는 데이터 모델링을 위한 많은 유연성을 제공한다.
또한 그래프는 발전성이 좋아서 데이터 구조 변경을 수용하게끔 그래프를 쉽게 확장할 수 있다.
사이퍼 질의 언어
속성 그래프를 위한 선언형 질의 언어
그림 1을 데이터의 일부를 사이퍼 질의로 표현
1
2
3
4
5
6
7
CREATE
(NAmerica:Location {name:'North America', type:'continent'}),
(USA:Location {name:'United States', type:'country' }),
(Idaho:Location {name:'Idaho', type:'state' }),
(Lucy:Person {name:'Lucy' }),
(Idaho) -[:WITHIN]-> (USA) -[:WITHIN]-> (NAmerica),
(Lucy) -[:BORN_IN]-> (Idaho)
예제 2 미국에서 유럽으로 이민 온 사람을 찾는 사이퍼 질의
1
2
3
4
MATCH
(person) -[:BORN_IN]-> () -[:WITHIN*0..]-> (us:Location {name:'United States'}),
(person) -[:LIVES_IN]-> () -[:WITHIN*0..]-> (eu:Location {name:'Europe'})
RETURN person.name
위의 질의는 다음과 같은 의미다.
- person은 어떤 정점을 향하는 BORNIN 유출 간선을 가진다.
이 정점에서 name 속성이 “United States”인 Location 유형의 정점에 도달할 때까지 일련의 WITHIN 유출 간선을 따라간다. - 같은 person 정점은 LIVESIN 유출 간선도 가진다.
이 간선과 WITHIN 유출 간선을 따라가면 결국 name 속성이 “Europe”인 Location 유형의 정점에 도달하게 된다.
질의를 실행하는 데는 여러 가지 방법이 있다.(책 참고)
하지만 선언형 질의 언어는 질의 최적화기가 효율적이라고 예측한 전략을 자동으로 선택하므로 보통 수행에 대해 자세히 지정할 필요가 없다.
SQL의 그래프 질의
예제 1에서 관계형 데이터베이스에서 그래프 데이터를 표현했다.
그렇다면 그래프 데이터를 관계형 구조로 넣어도 SQL을 사용해서 질의할 수 있을까?
가능은 하지만 어렵다.
관계형 데이터베이스에서는 보통 질의에 필요한 조인을 미리 알고 있지만
그래프 질의에서는 정점을 찾기 위해 가변적인 여러 간선을 순회해야 한다.
즉, 조인 수를 고정할 수 없다.
문제는 위의 사이퍼 질의에서 () - [:WITHIN*0..]-> () 문에 있다.
이는 0회 이상 WITHIN 간선을 따라가라는 의미다. <– 가변적인 여러 간선을 순회
SQL:1999 이후로 가변 순회 경로에 대한 질의 개념은 재귀 공통 테이블 식(recursive common table expression)(WITH RECURSIVE 문)을 사용해서 표현할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
WITH RECURSIVE
-- in_usa는 미국 내 모든 지역의 정점 ID 집합이다.
in_usa(vertex_id) AS (
SELECT vertexid FROM vertices WHERE properties->>'name' = 'United States'
UNION
SELECT edges.tail_vertex FROM edges
JOIN inusa ON edges.head_vertex = in_usa.vertex_id
WHERE edges.label = 'within'
),
-- in_europe은 유럽 내 모든 지역의 정점 ID 집합이다.
in_europe(vertex_id) AS (
SELECT vertexid FROM vertices WHERE properties->>'name' = 'Europe'
UNION
SELECT edges.tail_vertex FROM edges
JOIN ineurope ON edges.head_vertex = in_europe.vertex_id
WHERE edges.label = 'within'
),
-- born_in_usa는 미국에서 태어난 모든 사람의 정점 ID 집합이다.
born_in_usa(vertex_id) AS (
SELECT edges.tail_vertex FROM edges
JOIN inusa ON edges.head_vertex = in_usa.vertex_id
WHERE edges.label = 'born_in'
),
-- lives_in_europe은 유럽에서 태어난 모든 사람의 정점 ID 집합이다.
lives_in_europe(vertex_id) AS (
SELECT edges.tail_vertex FROM edges
JOIN ineurope ON edges.head_vertex = in_europe.vertex_id
WHERE edges.label = 'lives_in'
)
SELECT vertices.properties->>'name'
FROM vertices
-- 미국에서 태어나 유럽에서 자란 사람을 찾아 조인
JOIN bornin_usa ON vertices.vertex_id = born_in_usa.vertex_id
JOIN livesin_europe ON vertices.vertex_id = lives_in_europe.vertex_id;
사이퍼 질의 대비 SQL은 매우 길다.
이는 다양한 데이터 모델이 서로 다른 사용 사례를 지원하기 위해 설계됐다는 것을 보여준다.
따라서 애플리케이션에 적합한 데이터 모델을 선택하는 작업은 중요 하다.
트리플 저장소와 스파클
속성 그래프 모델과 거의 동일하다.
같은 개념을 다른 용어를 사용한다.
모든 정보를 (주어(subject), 서술어(predicate), 목적어(object)) 처럼 매우 간단한 세 부분 구문 형식으로 저장한다.
- 트리플의 주어는 그래프의 정점과 동등하다.
- 목적어는 다음과 같다.
- 문자열이나 숫자 같은 원시 데이터 값
트리플의 서술어와 목적어는 주어 정점의 속성의 키, 값과 동등 - 그래프의 다른 정점
서술어는 그래프의 간선
주어는 꼬리 정점
목적어는 머리 정점
- 문자열이나 숫자 같은 원시 데이터 값
그림1의 일부를 Turtle 트리플로 표현
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
@prefix : <urn:example:>.
_:lucy a :Person.
_:lucy :name "Lucy".
_:lucy :bornIn _:idaho.
_:idaho a :Location.
_:idaho :name "Idaho".
_:idaho :type "state".
_:idaho :within :usa.
_:usa a :Location.
_:usa :name "United States".
_:usa :type "country".
_:usa :within :namerica.
_:namerica a :Location.
_:namerica :name "North America".
_:namerica :type "continent".
- _:주어 서술어 목적어 형식
- 정점은 _:someName 형식
- 목적어가 원시 데이터인 경우
_:lucy :name “Lucy”
:name은 속성 키, “Lucy”는 속성 값 - 목적어가 다른 정점인 경우
_:idaho :within :usa
:within은 간선
스파클 질의 언어
RDF 데이터 모델을 사용한 트리플 저장소 질의 언어
예제2와 동일한 질의를 스파클로 표현
1
2
3
4
5
6
7
PREFIX : <urn:example:>
SELECT ?personName WHERE {
?person :name ?personName.
?person :bornIn / :within* / :name "United States".
?person :livesIn / :within* / :name "Europe".
}
스파클에서 변수는 물음표로 시작
사이퍼와 비교하면 아래와 같이 두 표현식이 동등
- (person) -[:BORNIN]-> () -[:WITHIN*0..]-> (location) #사이퍼
?person :bornIn / :within* ?location. #스파클 - (usa {name:’United States’}) #사이퍼
?usa :name “United States”. #스파클
그래프 데이터베이스와 네트워크 모델의 비교
코다실의 네트워크 모델과 그래프 데이터베이스는 몇 가지 중요한 차이점이 있다.
- 코다실은 다른 레코드 타입과 중첩 가능한 레코드 타입을 지정하는 스키마가 존재
그래프 데이터베이스는 제약 없음 - 코다실에서 특정 레코드에 도달하는 유일한 방법은 접근 경로를 탐색하는 방식
그래프 데이터베이스는 고유 ID를 가지고 임의 정점을 직접 참조 OR 색인을 사용해 빠르게 검색 - 코다실에서 레코드의 하위 항목은 정렬된 집합
그래프 데이터베이스에서 정점과 간선은 정렬하지 않음, 질의 결과를 정렬할 수 있음 - 코다실은 모든 질의는 명령형
그래프 데이터베이스는 명령형과 선언형 질의 모두 제공
초석: 데이터로그
오래된 언어이지만 이후 질의 언어의 기반이 되는 초석을 제공
데이터로그의 데이터 모델은 트리플 저장소 모델과 유사
하지만 조금 더 일반화
서술어(주어, 목적어) 형식
그림1의 일부데이터를 데이터로그 fact로 표현
1
2
3
4
5
6
7
8
9
10
11
12
13
name(namerica, 'North America').
type(namerica, continent).
name(usa, 'United States').
type(usa, country).
within(usa, namerica).
name(idaho, 'Idaho').
type(idaho, state).
within(idaho, usa).
name(lucy, 'Lucy').
born_in(lucy, idaho)
예제2와 동일한 질의를 데이터로그로 표현
1
2
3
4
5
6
7
8
9
10
11
12
13
within_recursive(Location, Name) :- name(Location, Name). /* Rule 1 */
within_recursive(Location, Name) :- within(Location, Via), /* Rule 2 */
within_recursive(Via, Name).
migrated(Name, BornIn, LivingIn) :- name(Person, Name), /* Rule 3 */
born_in(Person, BornLoc),
within_recursive(BornLoc, BornIn),
lives_in(Person, LivingLoc),
within_recursive(LivingLoc, LivingIn).
?- migrated(Who, 'United States', 'Europe').
/* Who = 'Lucy'. */
사이퍼와 스파클은 SELECT로 바로 질의하는 반면
데이터로그는 단계를 나눠 데이터베이스에 전달하는 규칙을 정의한다.
- :- 연산자의 오른편에 있는 모든 서술어를 찾으면 규칙이 적용
- :- 연산자의 왼편은 데이터베이스에 추가됨(변수는 대응된 값으로 대체)
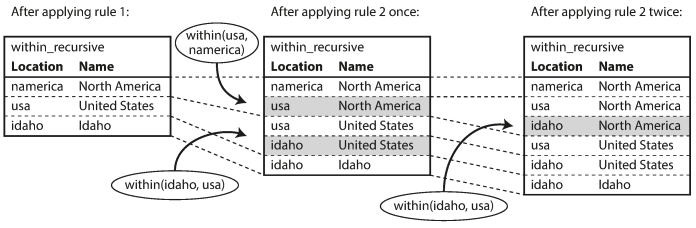
Rule 적용 과정
이제 rule 3을 적용해서 최종적으로 남은 사람이 결과가 된다
데이터로그 접근 방식은 이전에 설명한 질의 언어와는 다른 사고가 필요
하지만 규칙을 결합하거나 재사용할 수 있기 때문에 매우 강력한 접근 방식이다.
데이터가 복잡하면 더 효과적으로 대처할 수 있다.
정리
역사적으로 데이터를 하나의 큰 트리(계층 모델)로 표현하려고 노력했지만 다대다 관계를 표현하기에는 트리 구조가 적절하지 않았다.
이 문제를 해결하기 위해 *관계형 모델*이 고안됐다.
최근 관계형 모델에도 적합하지 않은 애플리케이션이 있다는 사실을 발견 했고 나온 것이 NoSQL이다.
NoSQL은 다음 두 가지 주요 갈래가 있다.
- 문서 데이터베이스
- 그래프 데이터베이스
한 모델은 다른 모델로 흉내 낼 수 있지만 위에서 확인 했다 싶이 사용이 어렵거나 애플리케이션에서 해결을 해야 하는 등 문제점이 있다.
이것이 바로 단일 만능 솔루션이 아닌 각기 목적에 맞는 다양한 시스템을 보유해야 하는 이유다.