
Table of Contents
트랜잭션과 락
JPA에서 제공하는 낙관적 락과 비관적 락에 대해 알아보자
트랜잭션과 격리 수준
트랜잭션은 ACID라 하는 원자성, 일관성, 격리성, 지속성을 보장해야 한다.
- 원자성: 트랜잭션 내에서 실행한 작업들은 마치 하나의 작업인 것처럼 모두 성공하거나 실패해야 한다.
- 일관성: 모든 트랜잭션은 일관성 있는 데이터베이스 상태를 유지해야 한다.
- 격리성: 동시에 실행되는 트랜잭션들이 서로에게 영향을 미치지 않도록 격리한다.
- 지속성: 트랜잭션을 성공적으로 끝내면 그 결과가 항상 기록되어야 한다.
트랜잭션 격리 수준
- READ UNCOMMITED(커밋되지 않은 읽기)
- READ COMMITED(커밋된 읽기)
- REPEATABLE READ(반복 가능한 읽기)
- SERIALIZABLE(직렬화 가능)
트랜잭션 격리 수준과 문제점
| 격리 수준 | DIRTY READ | NON-REPEATABLE READ | PHANTOM READ |
|---|---|---|---|
| READ UNCOMMITTED | O | O | O |
| READ COMMITTED | O | O | |
| REPEATABLE READ | O | ||
| SERIALIZABLE |
격리 수준에 따른 발생할 수 있는 문제점은 다음과 같다.
- DIRTY READ: 커밋되지 않은 수정중인 데이터를 읽을 수 있다.
- NON-REPEATABLE READ: 트랜잭션 1이 회원 A를 조회 중인데 갑자기 트랜잭션 2가 회원 A를 수정하고 커밋하면 트랜잭션 1이 다시 회원 A를 조회했을 때 수정된 데이터가 조회된다.
- PHANTOM READ: 트랜잭션1이 10살 이하의 회원을 조회했는데 트랜잭션 2가 5살 회원을 추가하고 커밋하면 트랜잭션1이 다시 10살 이하의 회원을 조회했을 때 회원 하나가 추가된 상태로 조회된다.
여기서 SERIALIZABLE은 가장 엄격한 트랜잭션 격리 수준이다. 위의 문제가 모두 발생하지 않지만, 동시성 처리 성능이 급격히 떨어질 수 있다.
낙관적 락과 비관적 락 기초
JPA의 영속성 컨텍스트를 적절히 활용하면 데이터베이스 트랜젝션이 READ COMMITTED 격리 수준이어도 APP 레벨에서 반복 가능한 읽기가 가능하다.
JPA는 데이터베이스 트랜잭션 격리 수준을 READ COMMITTED 정도로 가정한다.
만약 일부 로직에 더 높은 격리 수준이 필요하면 낙관적 락과 비관적 락 중 하나를 사용하면 된다.
- 낙관적 락은 이름 그대로 트랜잭션 대부분은 충돌이 발생하지 않는다고 낙관적으로 가정하는 방법이다.
이것은 DB가 제공하는 락 기능을 사용하는 것이 아니라 JPA가 제공하는 버전 관리 기능을 사용한다.
트랜잭션을 커밋하기 전까지는 트랜잭션의 충돌을 알 수 없다는 특징이 있다. - 비관적 락은 이름 그대로 트랜잭션의 충돌이 발생한다고 가정하고 우선 락을 걸고 보는 방법이다.
DB가 제공하는 락 기능을 사용한다.
여기에 추가로 DB 트랜잭션 범위를 넘어서는 문제도 있다.
예를 들어 두 번의 갱신 분실 문제가 있다. (2번의 수정이 동시에 발생하고 마지막 변경 사항만 남게 된다.)
두번의 갱신 분실 문제는 DB 트랜잭션의 범위를 넘어선다.
따라서 트랜잭션만으로는 문제를 해결할 수 없다.
이때는 3가지 선택 방법이 있다.
- 마지막 커밋만 인정하기
- 최초 커밋만 인정하기
- 충돌하는 갱신 내용 병합하기
JPA가 제공하는 버전 관리 기능을 사용하면 손쉽게 최초 커밋만 인정하기를 구현할 수 있다.
병합하기는 최초 커밋만 인정하기를 개발자가 직접 사용자를 위해 병합 방법을 제공해야 한다.
@Version
JPA가 제공하는 낙관적 락을 사용하려면 @Version 어노테이션을 사용해서 버전 관리 기능을 추가해야 한다.
@Version 적용 가능 타입은 다음과 같다.
- Long (long)
- Integer (int)
- Short (short)
Timestamp
@Entity public class Board { @Id private String id; private String title;
@Version private Integer version; }
이제부터 엔티티를 수정할 때 마다 버전이 하나씩 자동으로 증가한다.
그리고 엔티티를 수정할 때 조회 시점의 버전과 수정 시점의 버전이 다르면 예외가 발생한다.
따라서 버전 정보를 사용하면 최초 커밋만 인정 하기가 적용된다.
버전 정보 비교 방법
엔티티를 수정하고 트랜잭션을 커밋하면 영속성 컨텍스트를 플러시 하면서 UPDATE 쿼리를 실행하면서 버전 정보를 추가한다.
1
2
3
4
5
6
7
UPDATE BOARD
SET
TITLE = ?,
VERSION = ? (버전 +1)
WHERE
ID = ?
AND VERSION = ? (버전 비교)
@Version으로 추가한 버전 관리 필드는 JPA가 직접 관리하므로 개발자가 임의로 수정하면 안 된다.
만약 버전 값을 강제로 증가하려면 특별한 락 옵션을 선택하면 된다.
벌크 연산은 버전을 무시한다. 벌크 연산에서 버전을 증가하려면 버전 필드를 강제로 증가시켜야 한다.
JPA 락 사용
JPA를 사용할 때 추천하는 전략은 READ COMMITTED 트랜잭션 격리 수준 + 낙관적 버전 관리다.
락은 다음 위치에 적용할 수 있다.
- EntityManager.lock(), EntityManager.find(), EntityManager.refresh()
- Query.setLockMode() (TypeQuery 포함)
- @NamedQuery
JPA가 제공하는 락 옵션은 javax.persistence.LockModeType에 정의되어 있다.
| 락 모드 | 타입 | 설명 |
|---|---|---|
| 낙관적 락 | OPTIMISTIC | 낙관적 락을 사용한다. |
| 낙관적 락 | OPTIMISTICFORCEINCREMENT | 낙관적 락 + 버전정보를 강제로 증가 |
| 비관적 락 | PESSIMISTICREAD | 비관적 락, 읽기 락을 사용 |
| 비관적 락 | PESSIMISTICWRITE | 비관적 락, 쓰기 락을 사용 |
| 비관적 락 | PESSIMISTICFORCEINCREMENT | 비관적 락 + 버전정보를 강제로 증가 |
| 기타 | NONE | 락을 걸지 않는다 |
| 기타 | READ | JPA1.0 호환 기능 OPTIMISTIC과 동일 |
| 기타 | WRITE | JPA1.0 호환 기능 OPTIMISTICFORCEINCREMENT와 동일 |
JPA 낙관적 락
JPA가 제공하는 낙관적 락은 버전(@Version)을 사용한다.
낙관적 락은 트랜잭션을 커밋하는 시점에 충돌을 알 수 있다는 특징이 있다.
일부 JPA 구현체 중에서 @Version 컬럼 없이 낙관적 락을 허용하기도 하지만 추천하지는 않는다.
참고로 락 옵션 없이 @Version만 있어도 낙관적 락이 적용된다.
락 옵션을 사용하면 락을 더 세밀하게 제어할 수 있다.
NONE
락 옵션을 적용하지 않아도 엔티티에 @Version이 적용된 필드만 있으면 낙관적 락이 적용된다.
- 용도: 조회 시점부터 수정 시점까지를 보장
- 동작: 엔티티를 수정할 때 버전을 체크하면서 버전을 증가
- 이점: 두 번의 갱신 분실 문제를 예방
OPTIMISTIC
@Version만 적용했을 때는 엔티티를 수정해야 버전을 체크하지만
이 옵션을 추가하면 엔티티를 조회만 해도 버전을 체크 한다.
한번 조회한 엔티티는 트랜잭션을 종료할 때까지 다른 트랜잭션에서 변경하지 않음을 보장
- 용도: 조회 시점부터 트랜잭션이 끝날 때까지 조회한 엔티티가 변경되지 않음을 보장
- 동작: 트랜잭션을 커밋할 때 버전 정보를 조회해서 현재 엔티티의 버전과 같은지 검증, 만약 같지 않으면 예외가 발생
- 이점: OPTIMISTIC 옵션은 DIRTY READ와 NON-REPEATABLE READ를 방지
OPTIMISTICFORCEINCREMENT
- 용도: 논리적인 단위의 엔티티 묶음을 관리할 수 있다.
- 동작: 엔티티를 수정하지 않아도 트랜잭션을 커밋할 때 UPDATE 쿼리를 사용해서 버전 정보를 강제로 증가시킨다. 추가로 엔티티를 수정하면 수정 시 버전 UPDATE가 발생한다. 따라서 총 2번의 버전 증가가 나타날 수 있다.
- 이점: 강제로 버전을 증가해서 논리적인 단위의 엔티티 묶음을 버전 관리할 수 있다.
JPA 비관적 락
데이터베이스 트랜잭션 락 메커니즘에 의존하는 방법
주로 SQL 쿼리에 select for update 구문을 사용하면서 시작하고 버전 정보는 사용하지 않는다.
- 엔티티가 아닌 스칼라 타입을 조회할 때도 사용할 수 있다.
- 데이터를 수정하는 즉시 트랜잭션 충돌을 감지
PESSIMISTICWRITE
데이터베이스에 쓰기 락을 걸때 사용
- 용도: 데이터베이스에 쓰기 락을 건다.
- 동작: 데이터베이스에 select for update를 사용해서 락을 건다.
- 이점: NON-REPEATABLE READ를 방지한다. 락이 걸린 로우는 다른 트랜잭션이 수정할 수 없다.
PESSIMISTICREAD
데이터를 반복 읽기만 하고 수정하지 않는 용도로 락을 걸 때 사용
데이터베이스 대부분은 방언에 의해 PESSIMISTICWRITE로 동작
- MySQL: lock in share mode
- PostgreSQL: for share
PESSIMISTICFORCEINCREMENT
비관적 락중 유일하게 버전 정보를 사용
비관적 락이지만 버전 정보를 강제로 증가시킨다.
하이버네이트는 nowait를 지원하는 데이터베이스에 대해서 for update nowait 옵션을 적용한다.
- oracle: for update nowait
- PostgreSQL: for update nowait
- nowait를 지원하지 않으면 for update가 사용된다.
비관적 락과 타임아웃
비관적 락을 사용하면 락을 획득할 때까지 트랜잭션이 대기한다.
대기하다가 타임아웃 시간 대기 후 응답이 없으면 Javax.persistence.LockTimeoutException 예외가 발생한다.
타임아웃은 데이터베이스 특성에 따라 동작하지 않을 수 있다.
2차 캐시
1차 캐시와 2차 캐시
영속성 컨텍스트 내부에는 엔티티를 보관하는 저장소가 있는데 이것을 1차 캐시라 한다.
대부분의 JPA 구현체들은 애플리케이션 범위의 캐시를 지원하는데 이것을 공유 캐시 또는 2차 캐시라 한다.
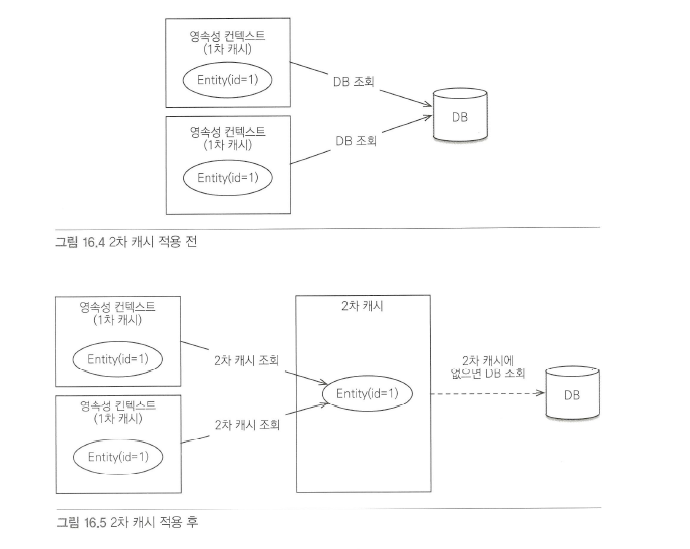
2차 캐시
2차 캐시를 적용하면 엔티티 매니저를 통해서 데이터를 조회할 때 우선 2차 캐시에서 찾고 없으면 데이터베이스에서 찾는다.
2차 캐시는 동시성을 극대화하려고 캐시한 객체를 직접 반환하지 않고 복사본을 만들어서 반환한다.
만약 캐시한 객체를 그대로 반환하면 여러 곳에서 같은 객체를 동시에 수정하는 문제가 발생할 수 있다.
특징은 다음 과 같다.
- 2차 캐시는 영속성 유닛 범위의 캐시다.
- 복사본을 만들어서 반환한다.
- 2차 캐시는 데이터베이스 기본 키를 기준으로 캐시하지만 영속성 컨텍스트가 다르면 객체 동일성(a==b)을 보장하지 않는다.
JPA 2차 캐시 기능
JPA 캐시 표준은 여러 구현체가 공통으로 사용하는 부분만 표준화해서 세밀한 설정을 하려면 구현체에 의존적인 기능을 사용해야 한다.
JPA 캐시 표준 기능은 다음과 같다.
캐시 모드 설정
2차 캐시를 사용하려면 @Cacheable 어노테이션을 사용하면 된다.
1
2
3
4
5
6
7
@Cacheable
@Entity
public class Member {
@Id @GeneratedValue
private Long id;
...
}
그리고 아래와 같이 persistence.xml에 shared-cache-mode를 설정해서 애플리케이션 전체에 캐시를 어떻게 적용할지 옵션을 설정해야 한다.
1
2
3
<persistence-unit name="test">
<shared-cache-mode>ENABLE_SELECTIVE</shared-cache-mode>
</persistence-unit>
캐시 모드 스프링 프레임워크 XML 설정
1
2
3
<bean id="entityManagerFactory" class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean">
<property name="sharedCacheMode" value="ENABLE_SELECCTIVE"/>
...
SharedCacheMode 설정
| 캐시 모드 | 설명 |
|---|---|
| ALL | 모든 엔티티를 캐시한다. |
| NONE | 캐시를 사용하지 않는다. |
| ENABLESELECTIVE | Cacheable(true)로 설정된 엔티티만 캐시를 적용한다. |
| DISABLESELECTIVE | 모든 엔티티를 캐시하는데 Cacheable(false)로 명시된 엔티티는 캐시하지 않는다. |
| UNSPECIFIED | JPA 구현체가 정의한 설정을 따른다. |
캐시 조회, 저장 방식 설정
캐시를 무시하고 데이터베이스를 직접 조회하거나 캐시를 갱신하려면 캐시 조회 모드와 캐시 보관 모드를 사용하면 된다.
1
em.setProperty("javax.persistence.cache.retrieveMode", CacheRetrieveMode.BYPASS);
캐시 조회 모드나 보관 모드에 따라서 사용할 프로퍼티와 옵션이 다르다.
프로퍼티 이름은 다음과 같다.
- javax.persistence.cache.retrieveMode: 캐시 조회 모드
- javax.persistence.cache.storeMode: 캐시 보관 모드
옵션은 다음과 같다.
- javax.persistence.CacheRetrieveMode: 캐시 조회 모드 설정 옵션
- javax.persistence.CacheStoreMode: 캐시 보관 모드 설정 옵션
캐시 조회 모드
1
2
3
4
public enum CacheRetrieveMode {
USE,
BYPASS
}
- USE: 캐시에서 조회, 기본 값
- BYPASS: 캐시를 무시하고 데이터베이스에서 직접 접근
캐시 보관 모드
1
2
3
4
5
public enum CacheStoreMode {
USE,
BYPASS,
REFRESH
}
- USE: 조회한 데이터를 캐시에 저장 하지만 이미 캐시에 있으면 캐시 데이터를 최신 상태로 갱신하지 않는다. 기본값
- BYPASS: 캐시에 저장하지 않는다.
- REFRESH: USE 전략에 추가로 데이터베이스에서 조회한 엔티티를 최신 상태로 다시 캐시한다.
캐시 모드는 EntityManager.setProperty()로 엔티티 매니저 단위로 설정하거나
더 세밀하게 EntityManager.find(), EntityManager.refresh()에 설정할 수 있다.
그리고 Query.setHint() (TypeQuery 포함)에 사용할 수 있다.
JPA 캐시 관리 API
JPA는 캐시를 관리하기 위한 javax.persistence.Cache 인터페이스를 제공한다.
Cache 인터페이스
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public interface Cache {
// 해당 엔티티가 캐시에 있는지 여부 확인
public boolean contains(Class cls, Object primaryKey);
// 해당 엔티티중 특정 실벽자를 가진 엔티티를 캐시에서 제거
public void evict(Class cls, Object primarykey);
// 해당 엔티티 전체를 캐시에서 제거
public void evict(Class cls);
// 모든 캐시 데이터 제거
public void evictAll();
// JPA Cache 구현체 조회
public <T> T unwrap(Class<T> cls);
}
하이버네이트와 EHCACHE 적용
하이버 네이트가 지원하는 캐시는 크게 3가지가 있다.
- 엔티티 캐시: 엔티티 단위로 캐시
- 컬렉션 캐시: 엔티티와 연관된 컬렉션을 캐시
컬렉션이 엔티티를 담고 있으면 식별자 값만 캐시(하이버네이트 기능) - 쿼리 캐시: 쿼리와 파라미터 정보를 키로 사용해서 캐시한다.
결과가 엔티티면 식별자 값만 캐시한다(하이버네이트 기능)
@Cache
| 속성 | 설명 |
|---|---|
| usage | CacheConcurrencyStrategy를 사용해서 캐시 동시성 전략을 설정 |
| region | 캐시 지역 설정 |
| include | 연관 객체를 캐시에 포함할지 선택, 기본 all |
CacheConcurrencyStrategy 속성
| 속성 | 설명 |
|---|---|
| NONE | 캐시를 설정하지 않는다. |
| READONLY | 읽기 전용으로 설정한다. 등록, 삭제는 가능하지만 수정은 불가능하다, 그래서 원본 객체를 반환 |
| NONSTRICTREADWRITE | 동시에 같은 엔티티를 수정하면 데이터 일관성이 깨질 수 있다. |
| READWRITE | READ COMMITTED 정도의 격리 수준을 보장한다. EHCACHE는 데이터를 수정하면 캐시 데이터도 같이 수정 |
| TRANSACTIONAL | 컨테이너 관리 환경에서 사용할 수 있다. 설정에 따라 REPEATABLE READ 정도의 격리 수준을 보장 |
캐시 동시성 전략 지원 여부
| Cache | read-only | nonstrict-read-write | read-write | transactional |
|---|---|---|---|---|
| ConcurrentHashMap | o | o | o | |
| EHCache | o | o | o | o |
| Infinispan | o | o |
캐시 영역
엔티티 캐시 영역은 기본값으로 [패키지 명 + 클래시 명]을 사용하고,
컬렉션 캐시 영역은 엔티티 캐시 영역 이름에 캐시한 컬렉션의 필드 명이 추가된다.
필요하면 @Cache(region = “customRegion”, …) 처럼 region 속성을 사용해서 캐시 영역을 직접 지정할 수 있다.
캐시 영역을 위한 접두사를 설정하려면 persistence.xml 설정에 hibernate.cache.regionprefix를 사용하면 된다.
core로 설정하면 core.jpabook.jpashop…으로 설정된다.
쿼리 캐시
쿼리 캐시는 쿼리와 파라미터 정보를 키로 사용해서 쿼리 결과를 캐시하는 방법이다.
쿼리 캐시를 적용하려면 영속성 유닛을 설정에 hibernate.cache.usequerycache 옵션을 꼭 true로 설정해야 한다.
그리고 쿼리 캐시를 적용하려는 쿼리 마다 org.hibernate.cacheable을 설정하는 힌트를 주면 된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
em.createQuery("select i from Item i", Item.class)
.setHint("org.hibernate.cacheable", true)
.getResultList();
@Entity
@NamedQuery(
hints = @QueryHint(name = "org.hibernate.cacheable",
value = "true"),
name = "Member.findByUsername",
query = "select m.address from Member m where m.name = :username"
)
public class Member {
...
}
쿼리 캐시 영역
hibernatecache.usequerycache 옵션을 true로 설정해서 쿼리 캐시를 활성화하면 다음 두 캐시 영역이 추가된다.
- org.hibernate.cache.internal.StandardCache: 쿼리 캐시를 저장하는 영역, 쿼리, 쿼리 결과 집합, 쿼리를 실행한 시점의 타임스탬프를 보관
- org.hibernate.cache.spi.UpdateTimestampsCache: 쿼리 캐시가 유효한지 확인하기 위해 쿼리 대상 테이블의 가장 최근 변경 시간을 저장하는 영역, 테이블 명과 해당 테이블의 최근 변경된 타임스탬프를 보관
쿼리 캐시를 적용하고 난 후에 쿼리 캐시가 사용하는 테이블에 조금이라도 변경이 있으면 데이터베이스에서 데이터를 읽어와서 쿼리 결과를 다시 캐시한다.
이제부터 엔티티에 변경하면 org.hibernate.cache.spi.UpdateTimestampsCache 캐시 영역에 해당 엔티티가 매핑한 테이블 이름으로 타임스탬프를 갱신한다.
쿼리를 실행하면 우선 StandardQueryCache 캐시 영역에서 타임스탬프를 조회한다.
그리고 쿼리가 사용하는 엔티티의 테이블의 UpdateTimestampsCache 캐시 영역에서 조회해서 테이블들의 타임스탬프를 확인한다.
캐시가 유효하지 않다면 데이터베이스에서 데이터를 조회해서 다시 캐시한다.
쿼리 캐시를 잘 활용하면 극적인 성능 향상이 있지만 빈번하게 변경이 있는 테이블에 사용하면 오히려 성능이 더 저하된다.
쿼리 캐시와 컬렉션 캐시의 주의점
쿼리 캐시와 컬렉션 캐시는 결과 집합의 식별자 값만 캐시한다.
이 식별자 값을 하나씩 엔티티 캐시에서 조회해서 실제 엔티티를 찾는다.
쿼리 캐시나 컬렉션 캐시만 사용하고 대상 엔티티에 엔티티 캐시를 적용하지 않으면 성능상 심각한 문제가 발생할 수 있다.
쿼리 캐시나 컬렉션 캐시는 식별자 값만 캐시하니, 엔티티 캐시를 사용하지 않으면 저장된 각 식별자 값으로 한 건씩 데이터베이스에서 조회한다.
따라서 쿼리 캐시나 컬렉션 캐시를 사용하면 결과 대상 엔티티에는 꼭 엔티티 캐시를 적용해야 한다.