
Table of Contents
- 스프링 데이터 JPA 설정
- 공통 인터페이스 기능
- 쿼리 메소드 기능
- 명세
- 사용자 정의 리포지토리 구현
- WEB 확장
- 스프링 데이터 JPA가 사용하는 구현체
- 스프링 데이터 JPA와 QueryDSL 통합
스프링 데이터 JPA 설정
1
2
3
@Configuration
@EnableJpaRepositories(basePackages = "검색할 패키지 위치")
public class AppConfig {}
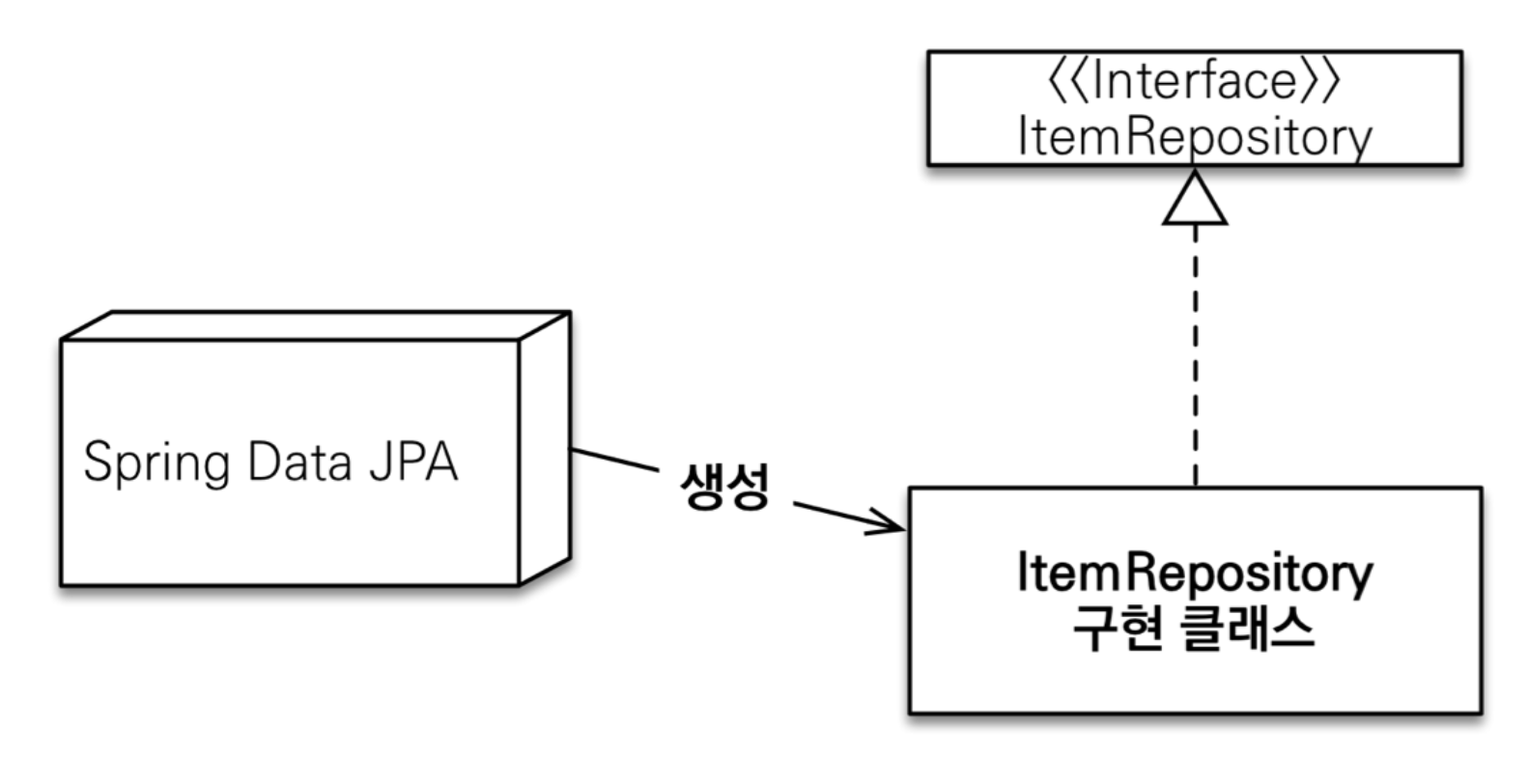
공통 인터페이스 기능
1
public interface MemberRepository extends JpaRepository<Member, Long> {}
스프링 데이터 JPA를 사용하는 가장 단순한 방법은 위의 인터페이스를 상속받는 것이다.
JpaRepository 인터페이스의 계층 구조
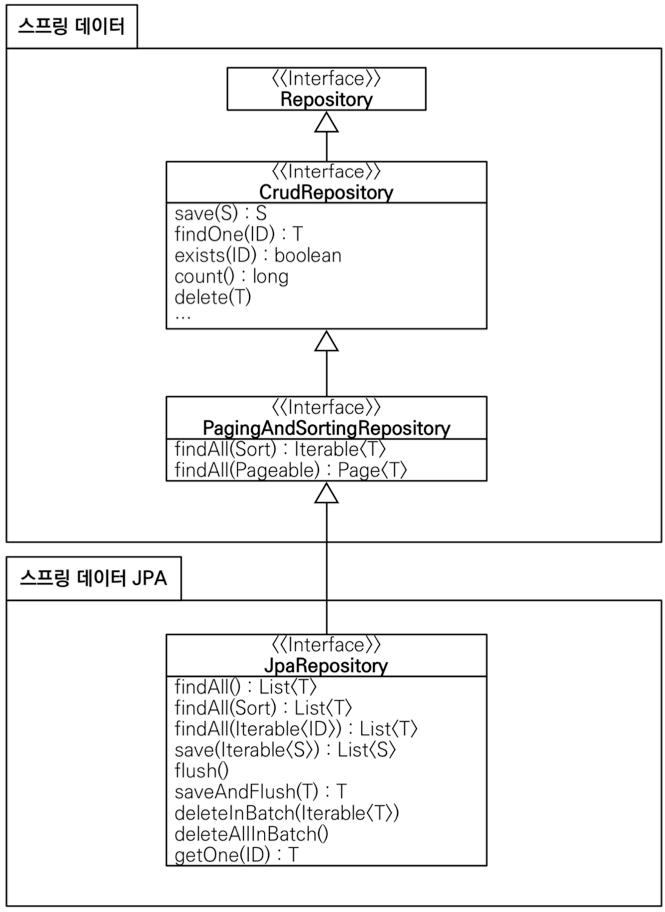
쿼리 메소드 기능
- 메소드 이름으로 쿼리 생성
- 메소드 이름으로 JPA NamedQuery 호출
- @Query 어노테이션을 사용해서 리포지토리 인터페이스에 쿼리 직접 정의
메소드 이름으로 쿼리 생성
1
2
3
public interface MemberRepository extends Repository<Member, Long> {
List<Member> findByEmailAndName(String email, String name);
}
인터페이스에 정의한 findByEmailAndName 메소드를 실행하면 스프링 데이터 JPA는 메소드 이름을 분석해서 JPQL을 생성하고 실행한다.
JPA NamedQuery
스프링 데이터 JPA는 메소드 이름으로 JPA Named 쿼리를 호출하는 기능을 제공한다.
JPA Named 쿼리는 이름 그대로 쿼리에 이름을 부여해서 사용하는 방법(어노테이션, XML등에 지정)
스프링 데이터 JPA를 사용하면 아래와 같이 메소드 이름만으로 Named 쿼리를 호출할 수 있다.
1
2
3
public interface MemberRepository extends JpaRepository<Member, Long> { // 여기 선언한 Member 도메인 클래스
List<Member> findByUsername(@Param("username") String username);
}
스프링 데이터 JPA는 선언한 “도메인 클래스 + . + 메소드 이름”으로 Named 쿼리를 찾아서 실행
만약 실행할 Named 쿼리가 없으면 메소드 이름으로 쿼리 생성 전략을 사용한다.
@Query, 리포지토리 메소드에 쿼리 정의
메소드에 정적 쿼리를 직접 작성하는 방법으로 이름 없는 Named 쿼리라 할 수 있다.
1
2
3
4
public interface MemberRepository extends JpaRepository<Member, Long> {
@Query("select m from Member m where m.username = ?1")
Member findByUsername(String username);
}
네이티브 SQL을 사용하려면 @Query 어노테이션에 nativeQuery = true를 설정하면 된다.
JPQL은 위치 기반 파라미터를 1부터 시작하지만 네이티브 SQL은 0부터 시작한다.
파라미터 바인딩
위치 기반 파라미터 바인딩과 이름 기반 파라미터 바인딩을 모두 지원
1
2
select m from Member m where m.username = ?1
select m from Member m where m.username = :name
기본 값은 위치 기반
이름 기반 파라미터 바인딩을 사용하려면 org.springframework.data.repository.query.Param 어노테이션을 사용하면 된다.
코드 가독성과 유지보수를 위해 이름 기반 파라미터 바인딩을 사용하자
벌크성 수정 쿼리
1
2
3
@Modifying
@Query("update Product p set p.price = p.price * 1.1 where p.stockAmount < :stockAmount"
int bulkPriceUp(@Param("stockAmount") String stockAmount);
스프링 데이터 JPA에서 벌크성 수정 삭제 쿼리는 org.springframework.data.repository.Modifying 어노테이션을 사용하면 된다.
벌크성 쿼리를 실행하고 나서 영속성 컨텍스트를 초기화하고 싶으면 @Modifying(clearAutomatically = true로 설정하면 된다.
기본값은 false이다.
반환 타입
결과가 한 건 이상이면 컬렉션 인터페이스를 사용
단건이면 반환 타입을 지정한다.
1
2
List<Member> findByName(String name);
Member findByEmail(String email);
조회 결과가 없으면 컬렉션은 빈 컬렉션을 반환하고 단건은 null을 반환한다.
단건을 기대하고 반환 타입을 지정했는데 결과가 2건 이상 조회되면 NonUniqueResultException 예외가 발생한다.
페이징과 정렬
- org.springframework.data.domain.Sort: 정렬 기능
- org.springframework.data.domain.Pageable: 페이징 기능(내부에 Sort 포함)
Pageable을 사용하면 반환 타입으로 List나 org.springframework.data.domain.Page를 사용할 수 있다.
Page를 사용하면 스프링 데이터 JPA는 페이징 기능을 제공하기 위해 검색된 전체 데이터 건수를 조회하는 count 쿼리를 추가로 호출한다.
1
2
3
public interface MemberRepository extends Repository<Member, Long> {
Page<Member> findByNameStartingWith(String name, Pageable Pageable);
}
위의 예제에서 두 번째 파라미터로 받은 Pageable은 인터페이스다.
해당 인터페이스를 구현한 PageRequest 객체를 사용한다.
힌트
JPA 쿼리 힌트를 사용하려면 QueryHints 어노테이션을 사용하면 된다.
이것은 SQL 힌트가 아니라 JPA 구현체에게 제공하는 힌트다.
1
@QueryHints(value = { @QueryHint(name = "org.hibernate.readOnly", value = "true")}, forCounting = true)
forCounting 속성은 반환 타입으로 Page 인터페이스를 적요앟면 추가로 호출하는 count 쿼리에도 쿼리 힌트를 적용할지를 설정하는 옵션이다.
Lock
1
2
@Lock(LockModeType.PESSIMISTIC_WIRTE)
List<Member> findByName(String name);
명세
DDD에서 명세라는 개념을 소개하는데, 스프링 데이터 JPA는 JPA Criteria로 이 개념을 사용할 수 있도록 지원한다.
Spectification은 컴포지트 패턴으로 구성되어 있어서 여러 Specification을 조합할 수 있다.
명세 기능을 사용하려면 JpaSpecificationExecutor 인터페이스를 상속받으면 된다.
1
public interface OrderRepository extends JpaRepository<Order, Long>, JpaSpecificationExecutor<Order> {}
JpaSpecificationexecutor는 Specification을 파라미터로 받아서 검색 조건으로 사용한다.
1
2
3
List<Order> result = orderRepository.findAll(
where(memberName(name)).and(isOrderStatus())
);
Specifications는 명세들을 조립할 수 있도록 도와주는 클래스인데 where, and, or, not 메소드를 제공한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
public class OrderSpec {
public static Specification<Order> memberNameLike(final String memberName) {
return new Specification<Order>() {
public Predicate toPredicate(Root<Order> root, CriteriaQuery<?> query, CriteriaBuilder builder) {
if (StringUtils.isEmpty(memberName)) return null;
Join<Order, Member> m = root.join("member", JoinType.INNER); //회원과 조인
return builder.like(m.<String>get("name"), "%" + memberName + "%");
}
};
}
public static Specification<Order> orderStatusEq(final OrderStatus orderStatus) {
return new Specification<Order>() {
public Predicate toPredicate(Root<Order> root, CriteriaQuery<?> query, CriteriaBuilder builder) {
if (orderStatus == null) return null;
return builder.equal(root.get("status"), orderStatus);
}
};
}
}
명세를 정의하려면 Specification 인터페이스를 구현하면 된다.
사용자 정의 리포지토리 구현
일단 사용자 정의 인터페이스를 작성해야 한다. 이름은 자유롭게 지으면 된다.
1
2
3
public interface CustomOrderRepository {
public List<Order> search();
}
이제 사용자 정의 인터페이스를 구현한 클래스를 작성
클래스 이름을 짓는 규칙이 있는데 리포지토리 인터페이스 이름 + Impl로 지어야 한다.
이렇게 하면 스프링 데이터 JPA가 사용자 정의 구현 클래스로 인식한다.
1
2
3
4
5
public class OrderRepositoryImpl implements CustomOrderRepository {
@Override
public List<Order> search() {
}
}
마지막으로 리포지토리 인터페이스에서 사용자 정의 인터페이스를 상속받으면 된다.
1
public interface OrderRepository extends JpaRepository<Order, Long>, CustomOrderRepository {}
WEB 확장
스프링 데이터 프로젝트는 스프링 MVC에서 사용할 수 있는 편리한 기능을 제공한다.
설정
스프링 데이터가 제공하는 Web 확장 기능을 활성화하려면 org.springframework.data.web.config.SpringDataWebConfiguration을 스프링 빈으로 등록하면 된다.
JavaConfig를 사용하면 EnableSpringDataWebSupport 어노테이션을 사용하면 된다.
설정을 완료하면 도메인 클래스 컨버터와 페이징과 정렬을 위한 HandlerMethodArgumentResolver가 스프링 빈으로 등록된다.
등록되는 도메인 클래스 컨버터는 DomainClassConverter이다.
도메인 클래스 컨버터 기능
도메인 클래스 컨버터는 HTTP 파라미터로 넘어온 엔티티의 아이디로 엔티티 객체를 찾아서 바인딩해준다.
1
2
3
4
5
@RequestMapping("member/memberUpdateForm")
public String memberUpdateForm(@RequestParam("id") Member member, Model model) {
model.addAtrribute("member", member);
return "member/memberSaveForm";
}
Http 요청으로 회원 아이디를 받지만 도메인 클래스 컨버터가 중간에 동작해서 아이디를 회원 인티티 객체로 변환해서 넘겨준다.
도메인 클래스 컨버터는 해당 엔티티와 관련된 리포지토리를 사용해서 엔티티를 찾는다.
페이징과 정렬 기능
스프링 데이터가 제공하는 페이징과 정렬 기능을 스프링 MVC에서 편리하게 사용할 수 있도록 HandlerMethodArgumentResolver를 제공한다.
- 페이징 기능: PageableHandlerMethodArgumentResolver
정렬 기능: SortHandlerMethodArgumentResolver
@RequestMapping(value = “/members”, method = RequestMethod.GET) public String list(Pageable pageable, Model model) {}
Pageable은 다음 요청 파라미터 정보로 만들어진다.
- page: 현재 페이지, 0부터 시작
- size: 한 페이지에 노출할 데이터 건수
- sort: 정렬 조건을 정의
접두사
사용해야 할 페이징 정보가 둘 이상이면 접두사를 사용해서 구분할 수 있다.
1
2
3
public String list(
@Qualifier("member") Pageable memberPageable,
@Qualifier("order") Pageable orderPageable, ...)
예 /members?memberpage=0&orderpage=1
기본값
Pageable의 기본값은 page=0, size=20이다.
변경하고 싶으면 @PageableDefault 어노테이션을 사용하면 된다.
1
2
@RequestMapping(..)
public String list(@PageableDefault(size = 12, sort = "name", direction = Sort.Direction.DESC) Pageable pageable)
스프링 데이터 JPA가 사용하는 구현체
스프링 데이터 JPA가 제공하는 공통 인터페이스는 SimpleJpaRepository 클래스가 구현한다.
- @Repository 적용: JPA 예외를 스프링이 추상화한 예외로 변환
- @Transactional 트랜잭션 적용: 데이터를 변경하는 메소드에 적용되어 있다.
- @Transactional(readOnly = true): 데이터를 조회하는 메소드에 적용되어 있다.
- save() 메소드: 새로운 엔티티면 저장하고 이미 있는 엔티티면 병합한다.
새로운 엔티티를 판단하는 전략
기본 전략은 엔티티의 식별자로 판단, 식별자가 객체일 때 null, 자바 기본 타입일 때 숫자 0 값이면 새로운 엔티티로 판단한다.
필요하면 Persistable 인터페이스를 구현해서 판단 로직을 변경할 수 있다.
스프링 데이터 JPA와 QueryDSL 통합
스프링 데이터 JPA는 2가지 방법으로 QueryDSL을 지원한다.
- QueryDslPredicateExecutor
- QueryDslRepositorySupport
QueryDslPredicateExecutor 사용
1
public interface ItemRepository extends JpaRepository<Item, Long>, QueryDslPredicateExecutor<Item> {}
QueryDslPredicateExecutor는 스프링 데이터 JPA에서 편리하게 QueryDSL을 사용할 수 있지만 기능에 한계가 있다.
예를 들어 join, fetch를 사용할 수 없다.
QueryDslRepositorySupport 사용
QueryDSL의 모든 기능을 사용하려면 JPAQuery 객체를 직접 생성해서 사용하면 된다.
이때 스프링 데이터 JPA가 제공하는 QueryDslRepositorySupport를 상속 받아 사용하면 조금 더 편리하게 QueryDSL을 사용할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
public interface CustomOrderRepository {
public List<Order> search(OrderSearch orderSearch);
}
public class OrderRepositoryImpl extends QueryDslRepositorySupport implements CustomOrderRepository {
public OrderRepositoryImpl() {
super(Order.class);
}
@Override
public List<Order> search(OrderSearch orderSearch) {
QOrder order = QOrder.order;
QMember member = QMember.member;
JPQLQuery query = from(order);
if (StringUtils.hasText(orderSearch.getMemberName())) {
query.leftJoin(order.member, member)
.where(member.name.contains(orderSearch.getMemberName()));
}
if (orderSearch.getOrderStatus() != null) {
query.where(order.status.eq(orderSearch.getOrderStatus()));
}
return query.list(order);
}
}